生命科学与技术学院史偈君团队开发新的核酸修饰测序通用比对算法,研究成果发表于《核酸研究》
来源:生命科学与技术学院
时间:2024-12-17 浏览:
随着表观遗传学和表观转录组学的快速发展,近年来涌现出大量RNA修饰和DNA修饰的检测方法。其中碱基转换(Base Conversion,简称为BC)方法由于能达到单碱基分辨率,对下游靶标发现和机制探索最为有利。按照碱基转换方式,BC方法可分为三类:单路转换,如用于检测5mC的C-to-T转换,或用于检测m6A的A-to-G转换;多路转换,如用于检测m1A的A-to-C/G/T转换;缺失转换,如用于检测假尿嘧啶的Ψ-to-deletion转换。结合高通量测序技术,BC方法能够识别全基因组/全转录组的修饰位点,精度优于基于免疫沉淀的方法。然而,多种多样的BC方法使数据分析面临着前所未有的挑战。目前,尚无生物信息学工具能够全面处理多样化的BC数据。数据比对是其中的关键难题,现有的主要策略包括“突变率策略”和“转换敏感策略”。前者将碱基转换视为错配而产生比对罚分,这会导致reads匹配到错误位置,或被错误丢弃;后者虽然在理论上更加合理,但现有工具尚不支持多路转换和缺失转换等复杂BC数据的处理。

为应对这一挑战,同济大学史偈君课题组与北京大学刘君课题组合作,基于核酸序列的位掩码设计和位数运算,开发了BASAL(BAse-conversion Sequencing ALigner)这一新型比对工具,能够准确处理转换碱基的比对罚分,并支持目前所有BC数据的分析(图1)。该研究成果以“BASAL: a universal mapping algorithm for nucleotide base-conversion sequencing”为题,于近日发表于《核酸研究》(Nucleic Acids Research)。
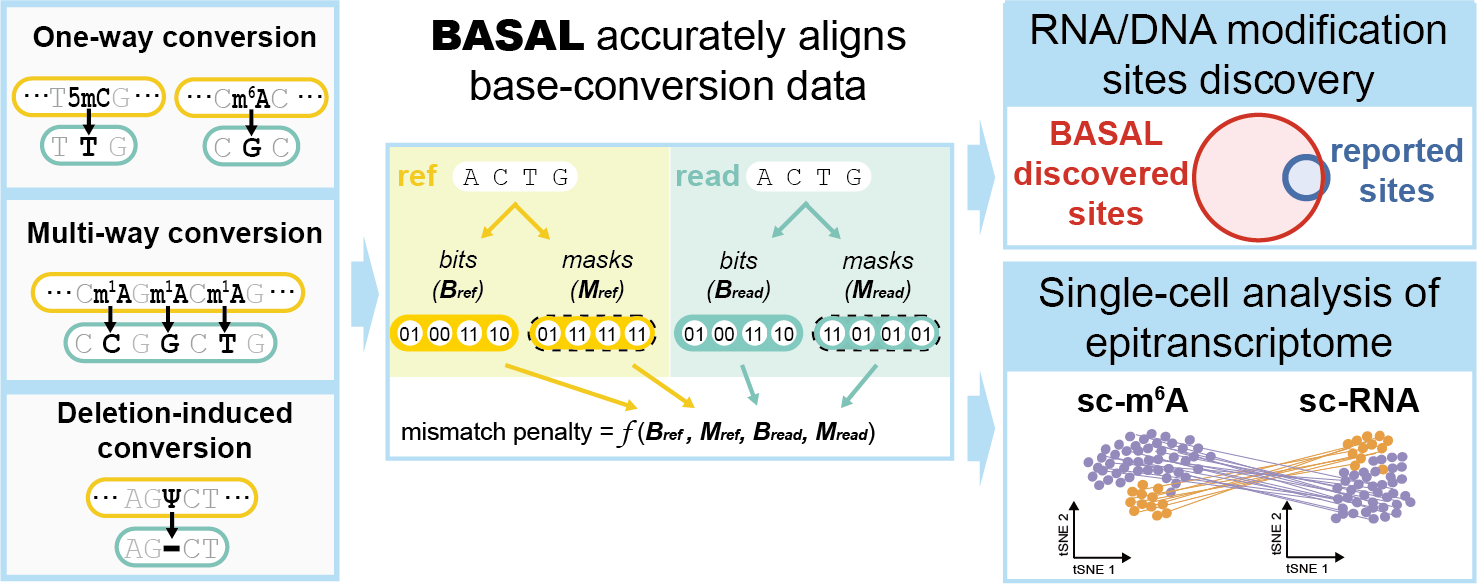
图1、成果概述
BASAL不仅能准确识别已知的修饰位点,还发现了大量新修饰位点(图2)。特别是对于检测RNA假尿嘧啶修饰(Ψ)的诱导缺失转化数据,BASAL比已有工具能发现更多的Ψ位点。通过比较BASAL新发现位点和已知位点的基序,发现BASAL在识别连续尿嘧啶序列环境中的Ψ方面具有独特的能力,这些位点已被证实与特定生物学功能密切相关。并且,BASAL新发现的Ψ位点也得到了质谱数据和qPCR实验数据的交叉验证,进一步证实了BASAL结果的可靠性。除bulk sequencing数据外,BASAL还改进了单细胞m6A数据的分析,发现了被前人忽视的细胞亚群和分化轨迹,凸显了其在解读单细胞表观转录组学数据方面的巨大潜力。

图2、BASAL识别大量未被已有工具发现的RNA假尿嘧啶(Ψ)位点
总之,BASAL是首个RNA和DNA修饰数据的通用比对算法,能够支持所有碱基转化测序数据的准确分析。由于能正确处理转换碱基的罚分,BASAL显著提高了测序数据的利用率和分析质量,不仅能发现更多可靠的RNA修饰位点,还能准确分析单细胞m6A数据,揭示与生物功能相关的细胞亚群和进化方向,将有助于推动表观基因组学/表观转录组学的突破性发现。
同济大学生命科学与技术学院史偈君研究员、北京大学生命科学学院刘君研究员为论文共同通讯作者,史偈君课题组的三年级博士生徐默萍、王淼和刘君课题组的博士生刘潇阳为论文共同第一作者。同济大学高亚威教授、史偈君课题组的二年级研究生罗婷婷在该研究工作中有重要贡献。另外,特别感谢北京脑科学与类脑研究中心Magdalena J.Koziol研究员及其博士生冯爽爽分享的单细胞m6A数据。该工作得到了光合基金与国家自然科学基金的资助。
论文链接:https://doi.org/10.1093/nar/gkae1201
BASAL工具发布链接:https://github.com/JiejunShi/BASAL



